
Choose the Right Model for Every Coding Task
If you’ve followed the previous two posts in this series — Teach Claude Code Your Project-Specific Skills and Make Qwen Code Actually Use Your Skills — you have all three of our agents wired up the same way. Skills encode the project's architecture. Hooks make sure those skills get invoked. The agents now produce code that looks like our code.
Now, let’s discuss which agent and model to actually use, and for what.
At ICS, we run Claude Sonnet, Claude Opus and a self-hosted Qwen3-Coder side by side. Each of them can solve some part of our work, and there is a large overlapping middle where any of them will do. Choosing well across that overlap is where the cost savings live.
The Cost and Token Equation
Frontier models are not cheap. Claude Opus is the most capable agent we run – and the most expensive per token. Claude Sonnet is a 50% step down in price and a smaller step down in capability. Qwen3-Coder running on hardware we already own is, at the margin, very nearly free. The GPUs are a sunk cost we’re paying whether or not the model is busy, and the power is equivalent to a small electric heater at full throttle.
What do these costs look like in a real project? A single task is small money while a team of engineers running coding agents all day for a quarter is not. Routing the right work to the right model can change a six-figure annual line item into a five-figure one without measurably changing the quality of the output.
Token discipline is part of the same picture: every reminder, every long agent file, every “actually, please re-read the spec” represents tokens that someone is paying for. The cheapest token is the one you did not need to spend.
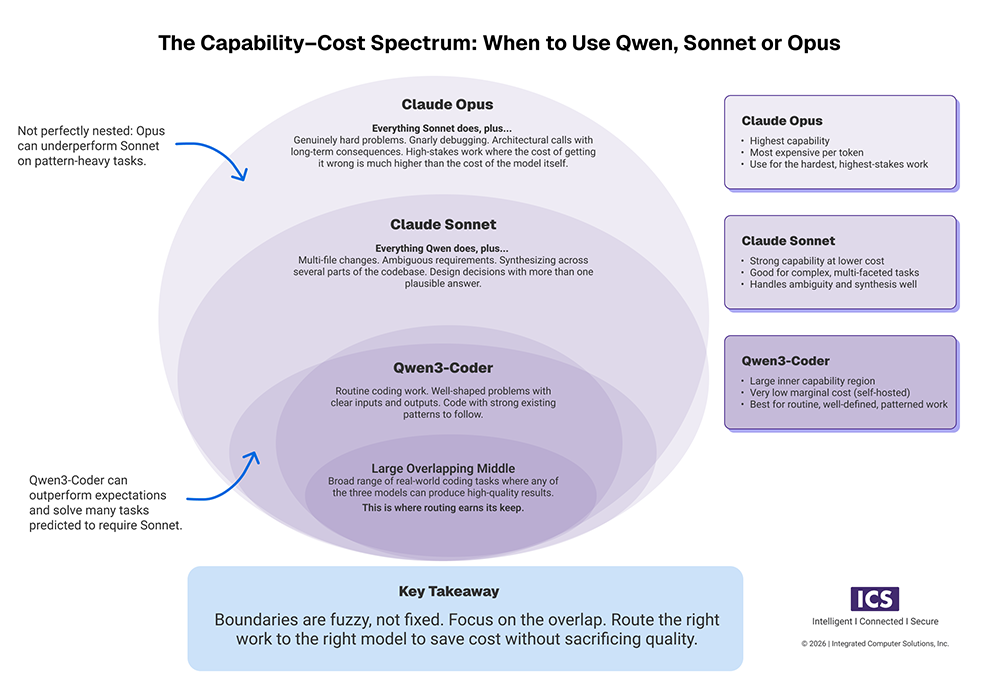
The Capability Venn Diagram
Think of the three models as concentric, overlapping regions of capability:
Qwen3-Coder covers a large inner region, including routine coding work, well-shaped problems with clear inputs and outputs, and code with strong existing patterns to follow.
Claude Sonnet covers everything Qwen3-Coder does plus a wider ring: multi-file changes, ambiguous requirements, code that requires synthesizing across several parts of the codebase, and design decisions that have more than one plausible answer.
Claude Opus covers everything Sonnet does plus a smaller outer ring of the genuinely hard problems, like gnarly debugging, architectural calls with long-term consequences, and work where the cost of getting it wrong is much higher than the cost of the model itself.
The diagram is roughly nested but not perfectly. Qwen3-Coder sometimes solves problems we would have predicted needed Sonnet, and Opus occasionally produces a worse answer than Sonnet on a task that turned out to be more pattern-matching than reasoning.
The point is not to draw the boundaries with surgical precision. It is to recognize that there is a large overlapping middle where any of the three will do, and that overlap is where routing earns its keep.
Route Routine Work to Qwen3-Coder
On our Qt/QML projects, with skills and hooks in place, Qwen3-Coder handles a surprisingly wide chunk of routine work. Tasks where Qwen3-Coder has been a strong default for us:
- Adding a new C++ class that follows an existing pattern — a new service behind a new IFoo interface, a corresponding mock, and a Google Test target.
- Adding a new QML component that mirrors an existing one and registering it in CMakeLists.
- Filling in tests for a class that already has a couple of test cases — Qwen3-Coder extends the pattern faster and more cheaply than reaching for Sonnet.
- Mechanical refactors: renaming a property across N files, splitting a header, moving a class between modules.
- Boilerplate-heavy edits where the architectural call has already been made and what remains is execution.
These are tasks with strong existing patterns and clear acceptance criteria. They are also tasks where Qwen3-Coder's lower per-token cost matters most, because a project the size of ours produces a lot of them. Routing all of this to a frontier model would be paying for capability we are not using.
Another surprising pro was how fast Qwen3-Coder is on the RTX6000 GPUs. During the day when Anthropic is most loaded, the local Qwen3-Coder returns generated code faster than Sonnet or Opus.
Use Sonnet for Most Engineering Tasks
Claude Sonnet is our default for anything that is not obviously routine. Sonnet handles:
- New features that touch multiple modules and require choosing between a few plausible designs.
- Bug investigations where the symptom and the cause are several steps apart.
- Code review and PR critique, especially when the question is whether a change fits the existing architecture.
- First drafts of new components in a new area of the codebase, where there is no strong existing pattern for Qwen3-Coder to follow.
- Anything that requires reading more of the codebase than fits comfortably in a single skill.
Sonnet is the model that gets the most exercise on our team. It is capable enough for the large majority of non-routine work and cheap enough that we do not feel bad reaching for it on the marginal task.
Reserve Opus for Expensive Mistakes
Claude Opus comes out for the small fraction of tasks where the cost of an iteration is high and the cost of the model is comparatively low:
Architectural decisions whose consequences are going to live in the codebase for a long time.
Debugging that has resisted multiple attempts with Sonnet — the kind of intermittent, multi-cause failure where the right hypothesis is non-obvious.
Cross-cutting refactors where getting the design wrong is much more expensive than the additional model spend.
Critical-path work on a deadline, where you would rather pay more for a higher first-attempt success rate than spend an extra debugging cycle.
We do not run Opus all day. We run it on the problems where its added capability translates directly into engineer-hours saved or risk avoided. Used that way, it is one of the cheapest tools in the stack — the tokens are dwarfed by the value of getting a hard call right the first time.
Practical Routing Heuristics
We do not have a hard router in front of our agents. The routing happens in the engineer's head when they decide what to type at the prompt. A few rules of thumb that have held up well:
- If the task has a clear template in the codebase, send it to Qwen. If you can name the existing class, component, or test it should look like, that is Qwen-shaped work.
- If the task requires choosing between several plausible designs, send it to Sonnet. If you can’t yet describe the answer in a sentence, you’ll want the better reasoner.
- If a Sonnet attempt fails for non-trivial reasons, escalate to Opus. Three Sonnet runs on a hard problem will often cost more in tokens (and your time) than one Opus run that gets it. It is tempting to stay on Opus, but remember to scale back after you get over the hurdles.
- If the code or context can’t leave your network, send it to Qwen. Privacy is not a tier of capability, but it is a hard routing constraint.
- Reuse the same skills across all three. Skills are the lingua franca that lets you move work between models without rewriting your conventions every time.
Why Skills Make This Possible
Routing only works if the models are speaking roughly the same language about your codebase. Without skills, each model would interpret “add a new service” differently, and you would either accept inconsistent code or spend the savings from cheaper models on rewriting their output.
With skills (see how we wrote ours), and with hooks ensuring those skills actually get invoked on the smaller model (read about hooks in part 2 of this series), the differences between Qwen, Sonnet and Opus become differences of capability and cost rather than differences of style.
Once that is true, you can route by capability. You can send the routine work to the cheap model, the substantive work to the middle model, and the genuinely hard work to the expensive model — and trust that the output of all three will fit the architecture you wrote down once.
Why We Run Frontier and Local Models Together
The picture we have landed on at ICS is not "frontier or local" but "frontier and local, with rules." Qwen3-Coder-80B-A3B handles the long tail of routine engineering. Claude Sonnet handles the daily mix of design, refactoring, and review. Claude Opus comes out for the problems whose answers we are going to live with for a long time. Skills keep all three honest. Hooks keep the local one disciplined.
The result is a stack that is materially cheaper than running everything on a frontier model and materially more consistent than running everything on a local one, which is the whole point.