
What You Need to Know About Over-the-Air Updates
Continuing our series on IoT device fleet management, let’s talk about requirements around over-the-air (OTA) updates. Distributed IoT device requirements are crucial for the dispersed systems that need to support remote connectivity, data transfer, and firmware or software version update.
The most important requirements, as described in the graphic below, revolve around the following:
- Security and integrity
- Usability
- Fault tolerance and recovery
- Integration
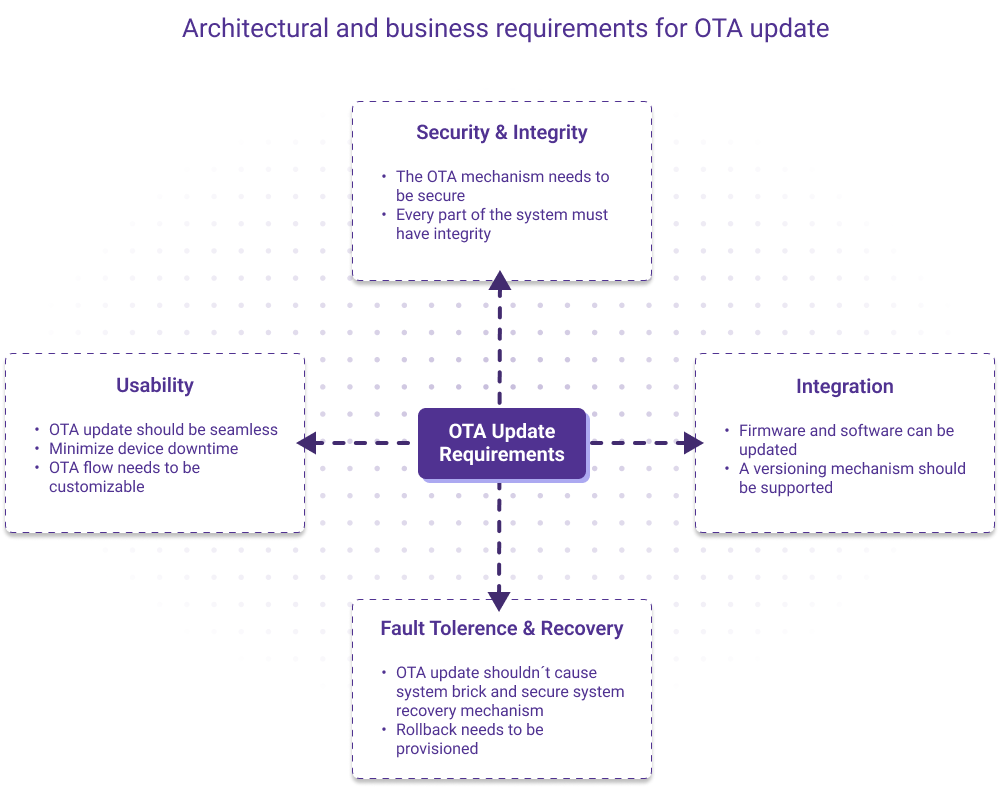
These requirements feed into the essential characteristics of a successful OTA strategy:
- An OTA update should never brick or put a device in an unknown state (reliability, integrity, recoverability)
- An OTA update should be secure, efficient and thrifty (usability, security)
- It should work with major cloud providers like AWS or Azure or in-house tech
- It should work on an open source platform (optional but highly desired)
The Risk of Power Failure
An OTA system with these characteristics would be able to mitigate significant issues in the event of a power failure. Without these characteristics, problems are likely. For instance, if a failure happens, the installed Iot device package manager (device software update tool) will end up in an unknown state with partially installed packages.
Though manual update of every device via SSH session can work for a fleet with a small number of devices, it is not a viable solution for fleets of thousands of devices. To avoid triggering OTA updates simultaneously for a large number of devices, updates can be organized over a set of devices grouped together for incremental roll-out.
A power failure can cause device software to become corrupted during an OTA update. This is how it might look:
- Build system is a part of OTA platform to compile and prepare a new release version
- Deploy artifact is deployment process over MQTT or HTTPs
- Power failure is an event of critical failure
- Brick is a final system state in a case of fatal error when Package Manager or Bootloader are incapable of recovering
Safe Update Options
So what can be done to prevent this? There are a few options.
Single versus double partitions
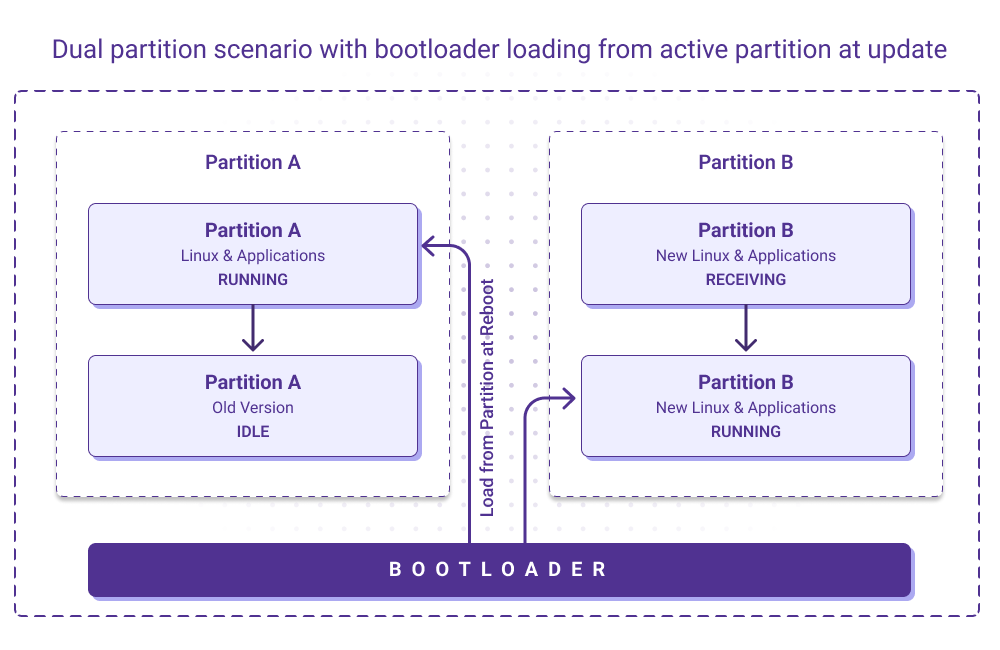
There are tools like OSTree that allow for updating both the Linux and the application without having a reserved space for downloadable images of a new version (using a single partition). But the same system integrity and reliability challenge can be addressed by allocating a special partition B along with major A (double partition) to avoid possible failure consequences, such as inconsistency in update.
By switching from A to B, loading the partition during the next reboot will be a safe and reliable update operation. If it fails to boot properly the system will mark partition B as invalid and revert to original functional partition A. The only downside of this approach is that it will cause some downtime of the target device.
(The dual partitions update approach is supported by Mender, while dual and single partition updates are also supported on such OTA platforms as SWUpdate and RAUC. We’ll explore some of these technologies in a moment.)
Containerized applications
Apart from single or dual partition update scenarios, there is an availability for a system to be updated at runtime. Let’s consider an embedded system. It usually comprises a Linux OS and several applications. In a single or dual partition update system, these elements together are considered to be a single artifact. Still, each of them could be updated independently. A portion of the update arrives with deployment of a new version of the application. Once the deployed container – more on this in a moment – is verified, the old container is stopped and replaced with a new instance. Finally the container is stored in a device's durable memory permanently. This is close to dual partition schema but implies a containerized approach.
A container is a feature that allows you to run your application within a Docker image. Docker is an open source containerization platform that allows developers to package applications into standardized executable components, combining application source code with OS libraries and the dependencies required to run that code.
Docker technology is one option for executing an OTA update – but there are drawbacks. Docker consumes a lot of resources and computing power, which limits its utility for embedded devices. Also, while Docker uses delta updates to update containers, a pure Docker solution is not atomic. (A guarantee of atomicity prevents updates to the database from occurring only partially.)
To deliver the benefits of Docker technology without the drawbacks, customized Docker-based platforms have emerged. Among the most popular are Balena and Torizon. To tackle the atomicity problem, these Docker based-solutions use the OSTree tool. OSTree is a library – actually libostree – that handles updates for filesystem trees, that is, the entire Linux root filesystem. OSTree generates delta updates between different versions of a filesystem. Each update is fully atomic. Basically, OSTree opens the possibility of achieving Docker delta updates on embedded devices.
In Part 3 of our fleet management series, we’ll focus on device fleet cybersecurity. If you missed part 1 in this series, start here.