
Exploring ZeroMQ's Request Reply Pattern
This blog is the third in an occasional series on ZeroMQ. For background, read part 1 and part 2.
ZeroMQ encourages us to think in terms of patterns — what we are going to do rather than how we're going to do it. We don't need to worry about the how since ZeroMQ takes care of it. The built-in core ZeroMQ patterns are:
-
Request/reply connects a set of clients to a set of services. This is a remote procedure call and task distribution pattern.
-
Pub-sub connects a set of publishers to a set of subscribers. This is a data distribution pattern.
-
Pipeline connects nodes in a fan-out/fan-in pattern that can have multiple steps and loops. This is a parallel task distribution and collection pattern.
-
Exclusive pair connects two sockets exclusively. This is a pattern for connecting two threads in a process and not to be confused with "normal" pairs of sockets.
Request Reply is arguably the most common pattern — client connects to a server, requests info, then receives a reply. Seems simple. But, the devil is in the details. It's name is Reliability. Basic Request Reply does not give us any indication of a cause if a reply doesn't arrive. It could be that there is nothing to reply yet. It could be transport congestion. Or the server has restarted and the client needs to reconnect. (ZeroMQ handles reconnection itself but a server can die so we should be able to handle this. Remember that ZeroMQ is a library — there is always application code! Don’t blame ZeroMQ. At least not yet.)
A word about reliability. We can only define reliability in terms of failure. If a system can handle a certain set of predefined failures, it can be called reliable with respect to those failures. That’s all. For example, the TCP protocol delivers packets reliably under normal conditions but can’t deliver anything if the network cable is disconnected. We have to describe a failure first, and then we can deal with it.
Here are some common causes of failure with decreasing probability:
-
Application code failure. Application can crash, can exhaust all the memory, can stop responding, you name it.
-
System code failure. The same reasons, although it should be more reliable than application code, but errors do happen. Think about running out of memory trying queuing messages for relatively big number of relatively slow clients.
-
Message overflow. Similar scenario, too many messages for too many slow clients. The difference is that in the former case system crashes while in the latter messages got lost. Not good either.
-
Network failure (for instance WiFi is out of range). ZeroMQ will reconnect automatically when we are back in range, but messages can get lost.
-
Hardware failure. Box died taking down all the processes. Stuff happens.
-
Exotic failure. Broken network cable. Power outage. Lightning strike. Earthquake.
We can architect our software system to be reliable with respect to most of these causes, though considering all exotic failure scenarios will skyrocket the cost of a project. But back to reliability. At the moment, we only care about reliable messaging so I'll focus on the Request Reply pattern.
Heartbeating
Heartbeating is a simple concept that's difficult to correctly implement. Immediate reaction when one hears about message or network reliability is to add heartbeats. Heartbeating solves the problem of knowing whether the peer is dead or alive. This problem is not specific to ZeroMQ. It is pretty simple to implement when you have one to one connection, though this is not the case in many real-world situations.
There are several approaches to heartbeating. Here's a look at a few.
Ignore Heartbeating
This seems to be the most common approach. Just hope it will work. Interesting enough, it has some merit in ZeroMQ philosophy of hiding peers. At the same time, there are few issues:
-
Application will leak memory as peers disconnect and reconnect if we use Router socket that tracks peers.
-
We can’t differentiate between “good” silence (no data) and “bad” silence (peer is dead) in Subscribe or Dealer data recipients.
-
TCP connection may just die in some networks if it stays silent for a long while. Sending something (technically, a "keep-alive" more than a heartbeat), will keep the network alive.
One-Way Heartbeat
Let’s send a heartbeat message from each node to its peers once a second, for example. It sounds good but it is not that simple. In fact, the only pattern that can be used is Publisher-Subscriber. Publisher can send a heartbeat, but Subscriber can’t talk back to Publisher. As an optimization, Publisher can send heartbeat only when there is no data. Subscriber, in turn, considers any data received from Publisher as a heartbeat.
Imagine a scenario when there is a network congestion or just a large amount of data to transfer, and the real heartbeat message is delayed. It may cause false timeout and unnecessary reconnection. In general, one should carefully consider the necessity of extra messages. Think about their impact on the mobile network and battery usage.
The other thing to consider carefully is that Publisher will drop messages for disappeared recipients. Push and Dealer sockets queue the messages. Now imagine scenario when the recipient disconnected and then reconnected and got all these queued heartbeats. More like a heart attack!
One-way heartbeat assumes the same timeout across whole network. In general, this assumption is incorrect. Some peers may require shorter timeout to detect faults rapidly, whereas others may need very relaxed heartbeats just to keep the connection alive.
Ping Pong Heartbeats
Another approach is Ping Pong peer-to-peer dialog. One peer sends Ping command to the other which replies with Pong command.Usually client sends Ping to server. But in many situations there is no “strict” client and server roles, so each peer can ping the other one and to expect pong in response. This works for any Router-based brokers. The optimization we discussed in previous case can be considered for Ping Pong too.
The most common use cases involve clients connecting to the server. There are three primary ways to connect and each method needs a specific approach to reliability. Here's a great overview from ZMQ's zguide:
-
Multiple clients talking directly to a single server. Use case: a single well-known server to which clients need to talk. Types of failure we aim to handle: server crashes and restarts, and network disconnects.
-
Multiple clients talking to a broker proxy that distributes work to multiple workers. Use case: service-oriented transaction processing. Types of failure we aim to handle: worker crashes and restarts, worker busy looping, worker overload, queue crashes and restarts, and network disconnects.
-
Multiple clients talking to multiple servers with no intermediary proxies. Use case: distributed services such as name resolution. Types of failure we aim to handle: service crashes and restarts, service busy looping, service overload, and network disconnects.
Reliable Request Reply
The basic Request Reply pattern (REQ socket on the client side with blocking send/receive on REP socket on server side) can’t handle well the most common types of failure. If server has died while processing Request, client is hang forever. The same thing happens when either Request or Reply message got lost. However with little extra work we can make this pattern working really well across distributed networks.
We are going to analyze reusable models that can help you design ZeroMQ architectures. ZeroMQ folks call them Pirate patterns. They include:
-
The Lazy Pirate pattern: reliable request reply from the client side
-
The Simple Pirate pattern: reliable request reply using load balancing
-
The Paranoid Pirate pattern: reliable request reply with heartbeating
Note that there are a few more patterns, which I'll analyze in my next post. These include:
-
The Majordomo pattern: service-oriented reliable queuing
-
The Titanic pattern: disk-based/disconnected reliable queuing
-
The Binary Star pattern: primary-backup server failover
-
The Freelance pattern: brokerless reliable request-reply
Lazy Pirate Pattern: Client-Side Reliability
We can get reliable request-reply with a simple change to the client side. Instead of using blocking Request Reply we can implement following
-
Poll the REQ socket and receive from it only when it's sure a reply has arrived.
-
Resend a request, if no reply has arrived within a timeout period.
-
Abandon the transaction if there is still no reply after several requests.
If you try to use a REQ socket in anything other than a strict send/receive fashion, you'll get an error, and we may send several requests before getting a reply. The brute force solution that works pretty well is to close and reopen the REQ socket after an error.
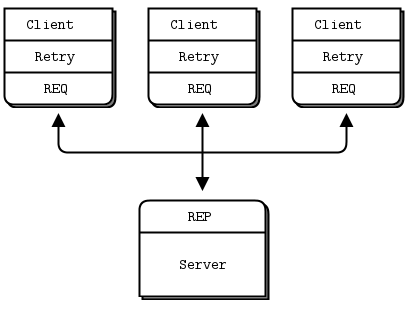
The client sequences each message and checks that replies come back exactly in order: that no requests or replies are lost, and no replies come back more than once, or out of order. Handling failures only at the client works when we have clients talking to a single server. It can handle a server crash, but only if the same server has been restarted.
To summarize: Lazy Pirate pattern is simple to understand and implement. It works easily with existing application code. ZeroMQ reconnects automatically to the same server, but it can’t failover to an alternative server.
Simple Pirate Pattern: Basic Reliable Queuing
Let’s extend the previous pattern by adding multiple servers (or more accurately, workers) and a queue proxy that allows clients to talk transparently to these workers.
In all these Pirate Patterns, workers are stateless. If they are connected to a shared database, or what not, it is irrelevant as we design our messaging architecture. Having a queue proxy means that workers can go off and on without clients knowing anything about it. At the same time, the queue proxy becomes a single point of failure. Otherwise it is simple and fairly robust topology.
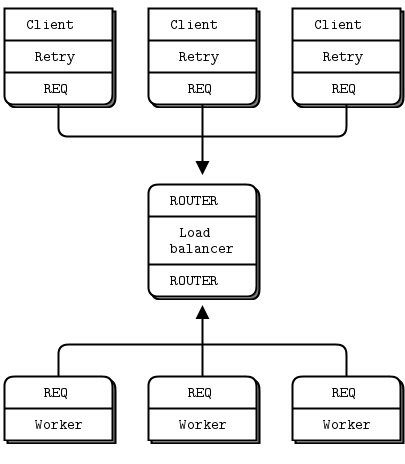
The basis for the queue proxy is the load balancing broker. We already have a retry mechanism in the client, we can use the same approach to handle dead or blocked workers. So using the load balancing pattern will work pretty well. This fits with ZeroMQ's philosophy that we can extend a peer-to-peer pattern like Request Reply by plugging naive proxies in the middle. Besides, we can use the same client we discussed in Lazy Pirate pattern. However worker uses Request socket in this case and not Reply socket as in previous.
Paranoid Pirate Pattern: Robust Reliable Queuing
Simple Pirate pattern works fairly well but still there are weaknesses.
-
As I mentioned, queue proxy is a single point of failure. If it crash and restart, the client will recover, but the workers won't. While ZeroMQ will reconnect workers' sockets automatically, as far as the newly started queue is concerned, the workers haven't signaled ready, so don't exist. We have to do heartbeating from queue to worker so that the worker can detect when the queue has gone away.
-
The queue does not detect worker failure, so if a worker dies while idle, the queue can't remove it from its worker queue until the queue sends it a request. The client waits and retries for nothing. It's not a critical problem, but it's not nice. To make this work properly, we do heartbeating from worker to queue, so that the queue can detect a lost worker at any stage.
Please welcome the Paranoid Pirate pattern.
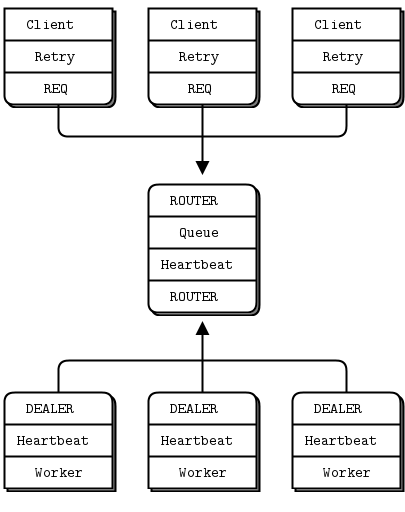
We use Dealer socket for worker for this pattern. This has the advantage of letting us send and receive messages at any time, rather than the lock-step send/receive that Request imposes. The downside of Dealer is that we have to do our own envelope management. It’s the first time we have to look at the internal structure of ZeroMQ message! It's not that complicated, but now we can appreciate how much magic is handled by ZeroMQ itself.
You should realize that Paranoid Pirate pattern is not interoperable with Simple Pirate pattern because of heartbeat. We go back to definitions of what is considered “interoperable.” The answer is simple: we have to define protocol. What version of the protocol peer supports? What does “server is ready” mean? What's the difference between data message and heartbeat message?
Here's the takeaway: start by defining and writing down the protocol. Surely, it will be your first step to success.